隨著數字化時代的到來,大數據已成為各行各業的核心競爭力。學習大數據不僅需要掌握基礎理論知識,還需精通一系列數據處理技術。本文將系統介紹大數據學習的核心內容,重點解析數據處理技術的應用與實踐。
一、大數據基礎理論知識
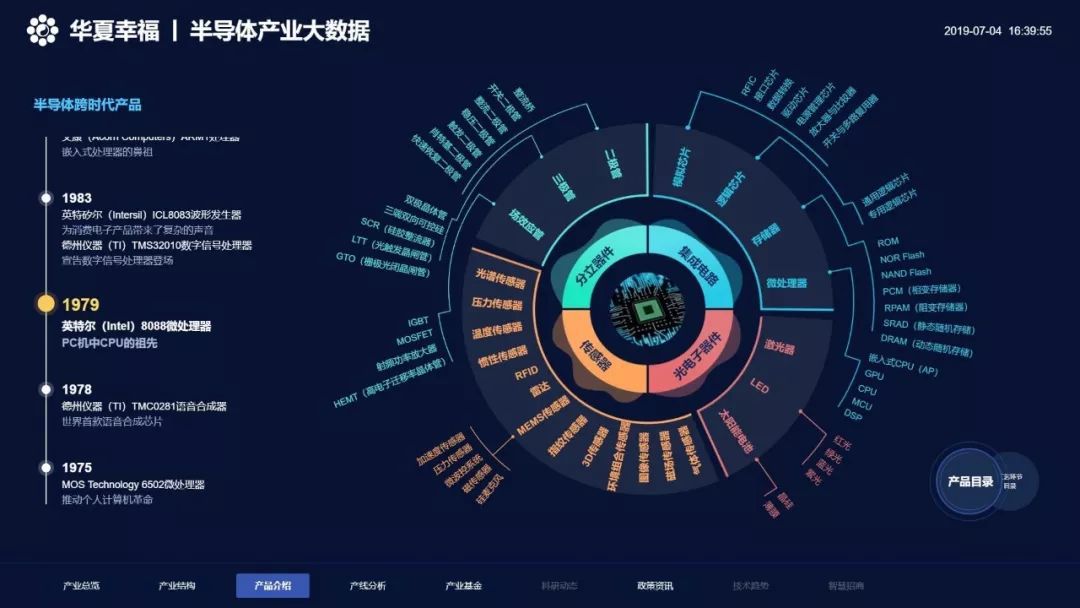
- 大數據概念與特征:理解大數據的5V特性(Volume、Velocity、Variety、Veracity、Value),了解大數據生態系統的發展歷程。
- 分布式系統原理:掌握分布式計算、存儲的基本概念,理解CAP定理、一致性模型等核心理論。
- 數據倉庫與數據湖:區分傳統數據倉庫與新興數據湖架構,了解各自的適用場景和優缺點。
二、數據處理技術體系
- 數據采集與集成
- 批量數據采集:Sqoop、DataX等工具的使用
- 實時數據流采集:Flume、Kafka等消息隊列技術
- 數據同步與ETL流程設計
- 數據存儲與管理
- 分布式文件系統:HDFS原理與運維
- NoSQL數據庫:HBase、Cassandra、MongoDB等
- NewSQL數據庫:TiDB、ClickHouse等
- 數據分區、分片與副本策略
- 數據處理與計算
- 批處理框架:MapReduce編程模型、Spark Core
- 流處理技術:Spark Streaming、Flink、Storm
- 圖計算框架:GraphX、Giraph
- 內存計算與優化技術
- 數據查詢與分析
- SQL-on-Hadoop工具:Hive、Impala、Presto
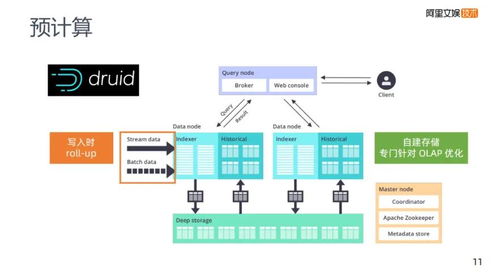
- 交互式查詢引擎:Druid、Kylin
- 數據可視化與報表工具
- 數據治理與質量
- 元數據管理:Atlas、DataHub
- 數據血緣分析
- 數據質量監控與校驗
- 數據安全與權限管理
三、大數據平臺與架構
- Hadoop生態系統:掌握HDFS、YARN、MapReduce等核心組件
- 云原生大數據平臺:了解在Kubernetes上部署大數據組件的實踐
- 混合架構設計:Lambda架構與Kappa架構的比較與選擇
四、實踐技能要求
- 編程語言:熟練掌握Java、Scala、Python等語言
- Linux系統操作:熟練使用Shell腳本進行系統管理
- 容器化技術:Docker、Kubernetes的部署與管理
- 監控與調優:集群性能監控、故障排查與優化
五、進階學習方向
- 機器學習與人工智能:Spark MLlib、TensorFlow等框架
- 實時推薦系統架構
- 數據湖倉一體化趨勢
- 數據中臺建設方法論
大數據學習是一個系統工程,需要從理論基礎到技術實踐全面掌握。數據處理技術作為核心環節,既需要理解各種框架的原理,又要具備實際部署和優化的能力。隨著技術的不斷發展,大數據從業者還需要保持持續學習的態度,緊跟技術演進趨勢,才能在數據驅動的時代保持競爭力。