在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,高效、可靠地處理海量信息已成為企業(yè)競(jìng)爭(zhēng)的核心能力。本文將系統(tǒng)性地探討大數(shù)據(jù)處理的基礎(chǔ)架構(gòu)、兩種核心數(shù)據(jù)處理模式(OLTP與OLAP)的區(qū)別,并深入解析以數(shù)據(jù)庫(kù)、Hadoop、Spark、Hive及Flink為代表的現(xiàn)代大數(shù)據(jù)技術(shù)生態(tài)。
一、 大數(shù)據(jù)處理的基礎(chǔ)架構(gòu)
大數(shù)據(jù)基礎(chǔ)架構(gòu)是一個(gè)復(fù)雜的分布式系統(tǒng)集合,其核心目標(biāo)在于實(shí)現(xiàn)對(duì)海量、多樣、高速(即大數(shù)據(jù)的“3V”特性:Volume, Variety, Velocity)數(shù)據(jù)的存儲(chǔ)、處理和分析。一個(gè)典型的大數(shù)據(jù)技術(shù)棧通常包含以下層級(jí):
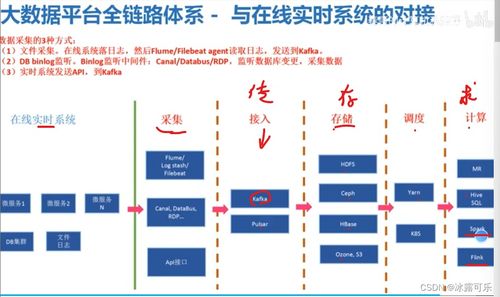
- 數(shù)據(jù)采集與集成層:負(fù)責(zé)從各種來(lái)源(如日志、傳感器、數(shù)據(jù)庫(kù)、應(yīng)用程序)實(shí)時(shí)或批量地采集數(shù)據(jù)。常用工具有Flume、Kafka、Sqoop等。
- 數(shù)據(jù)存儲(chǔ)層:提供海量數(shù)據(jù)的持久化存儲(chǔ)。這既包括傳統(tǒng)的結(jié)構(gòu)化數(shù)據(jù)存儲(chǔ)(如關(guān)系型數(shù)據(jù)庫(kù)),也包括為大規(guī)模非結(jié)構(gòu)化或半結(jié)構(gòu)化數(shù)據(jù)設(shè)計(jì)的分布式文件系統(tǒng)(如HDFS)和NoSQL數(shù)據(jù)庫(kù)(如HBase、Cassandra)。
- 計(jì)算與處理層:這是大數(shù)據(jù)架構(gòu)的核心,負(fù)責(zé)對(duì)存儲(chǔ)層的數(shù)據(jù)進(jìn)行各種計(jì)算。它包括批處理框架(如MapReduce、Spark Core)、流處理框架(如Flink、Storm、Spark Streaming)以及交互式查詢引擎(如Impala、Presto)。
- 資源管理與協(xié)調(diào)層:為上層應(yīng)用提供統(tǒng)一的資源調(diào)度、作業(yè)管理和集群協(xié)調(diào)服務(wù)。YARN(Yet Another Resource Negotiator)是Hadoop生態(tài)中的核心資源管理器,而ZooKeeper則提供分布式協(xié)調(diào)服務(wù)。
- 數(shù)據(jù)查詢與分析層:為用戶和應(yīng)用程序提供訪問(wèn)和處理數(shù)據(jù)的接口,包括SQL-on-Hadoop工具(如Hive)、數(shù)據(jù)倉(cāng)庫(kù)、OLAP引擎以及各類(lèi)機(jī)器學(xué)習(xí)庫(kù)。
- 數(shù)據(jù)治理與安全層:確保數(shù)據(jù)的質(zhì)量、一致性、安全性和合規(guī)性,涉及元數(shù)據(jù)管理、數(shù)據(jù)血緣、訪問(wèn)控制等。
二、 OLTP與OLAP:兩種關(guān)鍵的數(shù)據(jù)處理模式
理解聯(lián)機(jī)事務(wù)處理(OLTP)與聯(lián)機(jī)分析處理(OLAP)的區(qū)別,是設(shè)計(jì)數(shù)據(jù)系統(tǒng)的基石。
- OLTP(聯(lián)機(jī)事務(wù)處理):
- 核心目標(biāo):支持日常高頻的業(yè)務(wù)操作,如訂單錄入、銀行轉(zhuǎn)賬、庫(kù)存更新等。強(qiáng)調(diào)高并發(fā)、低延遲、強(qiáng)一致性的短小事務(wù)。
- 數(shù)據(jù)特征:處理的是最新的、細(xì)節(jié)性的操作數(shù)據(jù),數(shù)據(jù)量相對(duì)較小但更新頻繁。
- 數(shù)據(jù)庫(kù)設(shè)計(jì):通常采用規(guī)范化的關(guān)系模型(第三范式),以最大化數(shù)據(jù)一致性和減少冗余。
- 典型技術(shù):傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù),如MySQL、Oracle、PostgreSQL。
- OLAP(聯(lián)機(jī)分析處理):
- 核心目標(biāo):支持復(fù)雜的分析查詢,為商業(yè)智能(BI)、數(shù)據(jù)分析和決策支持服務(wù)。強(qiáng)調(diào)大數(shù)據(jù)量的快速、復(fù)雜查詢,關(guān)注數(shù)據(jù)的匯總、聚合和多維分析。
- 數(shù)據(jù)特征:處理的是歷史的、聚合的、來(lái)自多個(gè)OLTP系統(tǒng)的數(shù)據(jù),數(shù)據(jù)量巨大,但更新不頻繁(批量加載)。
- 數(shù)據(jù)庫(kù)設(shè)計(jì):通常采用反規(guī)范化的模型,如星型模式或雪花模式,以優(yōu)化查詢性能。
- 典型技術(shù):數(shù)據(jù)倉(cāng)庫(kù)(如Teradata)、列式存儲(chǔ)數(shù)據(jù)庫(kù)(如ClickHouse)、以及Hadoop/Spark生態(tài)中的分析工具。
核心區(qū)別:OLTP是面向“操作”的,確保每筆業(yè)務(wù)準(zhǔn)確無(wú)誤地完成;OLAP是面向“分析”的,旨在從海量歷史數(shù)據(jù)中洞察規(guī)律。兩者相輔相成,OLTP系統(tǒng)是數(shù)據(jù)的“生產(chǎn)者”,而OLAP系統(tǒng)是數(shù)據(jù)的“消費(fèi)者”。
三、 現(xiàn)代大數(shù)據(jù)核心技術(shù)與數(shù)據(jù)處理范式
隨著數(shù)據(jù)規(guī)模與復(fù)雜性激增,超越傳統(tǒng)數(shù)據(jù)庫(kù)的大數(shù)據(jù)技術(shù)棧應(yīng)運(yùn)而生。
- 數(shù)據(jù)庫(kù)技術(shù)的演進(jìn):
- 傳統(tǒng)關(guān)系型數(shù)據(jù)庫(kù)(RDBMS)仍是OLTP場(chǎng)景的霸主。
- NoSQL數(shù)據(jù)庫(kù)(如MongoDB、Cassandra)為應(yīng)對(duì)非結(jié)構(gòu)化數(shù)據(jù)、高可擴(kuò)展性和靈活模式而生。
- NewSQL數(shù)據(jù)庫(kù)(如Google Spanner、TiDB)試圖兼顧SQL的強(qiáng)一致性與NoSQL的橫向擴(kuò)展能力。
- 云原生數(shù)據(jù)庫(kù)與數(shù)據(jù)倉(cāng)庫(kù)(如Snowflake、Amazon Redshift)提供了彈性和易用性。
- Hadoop生態(tài):批處理的基石
- Hadoop:一個(gè)開(kāi)源分布式計(jì)算框架,核心是HDFS(分布式存儲(chǔ))和MapReduce(分布式計(jì)算模型)。它奠定了低成本、可擴(kuò)展處理海量數(shù)據(jù)的基石,但MapReduce編程復(fù)雜且延遲高,適合離線批處理。
- Hive:構(gòu)建在Hadoop之上的數(shù)據(jù)倉(cāng)庫(kù)工具。它將用戶編寫(xiě)的類(lèi)SQL語(yǔ)句(HiveQL)轉(zhuǎn)換為MapReduce任務(wù)執(zhí)行,大大降低了大數(shù)據(jù)分析的門(mén)檻,是早期進(jìn)行大規(guī)模批處理分析的關(guān)鍵組件。
- Spark:統(tǒng)一計(jì)算引擎的革新
- Spark:一個(gè)基于內(nèi)存的統(tǒng)一分布式計(jì)算引擎。它通過(guò)引入彈性分布式數(shù)據(jù)集(RDD)及更高級(jí)的DAG執(zhí)行引擎,比MapReduce快數(shù)十到數(shù)百倍。
- 核心優(yōu)勢(shì):提供了統(tǒng)一的編程模型(Spark Core),可同時(shí)支持批處理、交互式查詢(Spark SQL)、流處理(Structured Streaming)、機(jī)器學(xué)習(xí)(MLlib)和圖計(jì)算(GraphX),實(shí)現(xiàn)了“一棧式”解決方案。
- Flink:流處理為先的架構(gòu)
- Flink:一個(gè)真正的流處理引擎,采用“流是本質(zhì),批是特例”的設(shè)計(jì)哲學(xué)。其核心是分布式數(shù)據(jù)流引擎。
- 核心優(yōu)勢(shì):提供高吞吐、低延遲、Exactly-Once語(yǔ)義的流處理能力。其批處理被視為有界流來(lái)處理。Flink在復(fù)雜的事件驅(qū)動(dòng)型應(yīng)用和實(shí)時(shí)數(shù)據(jù)分析場(chǎng)景中表現(xiàn)卓越,與Spark Structured Streaming形成競(jìng)爭(zhēng)。
四、 技術(shù)選型與融合趨勢(shì)
選擇合適的技術(shù)取決于具體的業(yè)務(wù)需求:
- 高頻事務(wù)操作:首選OLTP關(guān)系型數(shù)據(jù)庫(kù)或NewSQL。
- 離線大數(shù)據(jù)分析、歷史報(bào)表:Hive on Hadoop/Spark 仍是可靠選擇。
- 需要融合批處理、交互查詢和機(jī)器學(xué)習(xí)的復(fù)雜分析:Spark生態(tài)是強(qiáng)大的一體化平臺(tái)。
- 對(duì)延遲極其敏感的實(shí)時(shí)監(jiān)控、實(shí)時(shí)風(fēng)控、CEP(復(fù)雜事件處理):Flink是當(dāng)今的業(yè)界標(biāo)桿。
現(xiàn)代大數(shù)據(jù)架構(gòu)正朝著流批一體和湖倉(cāng)一體的方向演進(jìn)。例如,Spark和Flink都在努力統(tǒng)一流和批的編程模型;而將數(shù)據(jù)湖的靈活性與數(shù)據(jù)倉(cāng)庫(kù)的管理性能相結(jié)合的架構(gòu),正成為企業(yè)數(shù)據(jù)平臺(tái)的新標(biāo)準(zhǔn)。理解這些基礎(chǔ)架構(gòu)、模式與技術(shù)的差異與聯(lián)系,是構(gòu)建高效、面向未來(lái)數(shù)據(jù)系統(tǒng)的關(guān)鍵第一步。