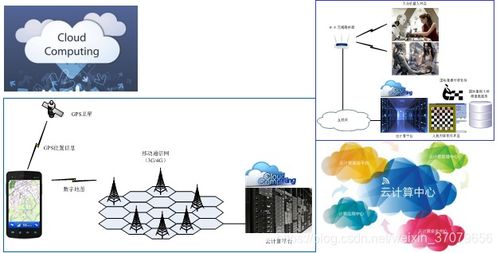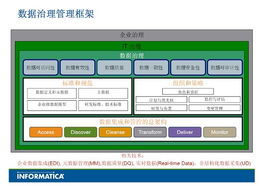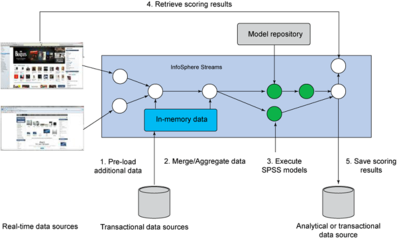
隨著大數據時代的到來,數據量呈現爆炸式增長,傳統的數據處理技術面臨前所未有的挑戰。SPSS(Statistical Package for the Social Sciences)作為一種成熟的統計分析軟件,憑借其強大的統計建模和可視化功能,被廣泛應用于大數據處理領域。本文將探討SPSS如何融入大數據處理流程,分析其優勢與局限,并提出有效的應用策略。
SPSS在大數據處理中發揮著重要作用。其核心優勢在于提供直觀的用戶界面和豐富的統計方法,如描述性統計、回歸分析、聚類分析和因子分析等。用戶可以通過SPSS Modeler等工具處理大規模數據集,結合數據挖掘技術識別隱藏模式。例如,在商業智能領域,企業利用SPSS分析客戶行為數據,優化營銷策略;在醫療健康領域,研究人員處理海量臨床數據,預測疾病風險。SPSS的可視化功能還能將復雜數據轉化為圖表,幫助決策者快速理解結果。
SPSS在處理超大規模數據時存在一定局限。由于其最初設計面向中小型數據集,當數據量達到TB或PB級別時,可能面臨性能瓶頸,如內存不足或處理速度慢。為此,用戶需結合其他大數據技術,如Hadoop或Spark,進行數據預處理和分布式計算。例如,可以先用Hadoop進行數據清洗和聚合,再將結果導入SPSS進行深入分析。這種混合模式既能發揮SPSS的統計分析優勢,又能利用大數據平臺的高效處理能力。
為優化SPSS在大數據中的應用,建議采取以下策略:一是加強數據預處理,通過抽樣或降維技術減少數據規模;二是利用SPSS的擴展功能,如與Python或R集成,實現自定義分析腳本;三是注重數據安全與隱私保護,確保合規性。未來,隨著SPSS不斷升級,其與云計算的結合將進一步拓展大數據分析的可能性。
SPSS作為一款經典的分析工具,在大數據時代仍具有重要價值。通過合理整合其他技術,它能有效提升數據處理的效率與深度,為各行業提供有力的決策支持。